そろそろマフラーを巻こうかという季節,いかがお過ごしでしょうか.B3の二宮洸太とB4の松山直人です.
今回は2019年10月25日と26日に公立はこだて未来大学にて行われた,第2回コミック工学研究会に参加しました.その報告をここに記します.

コミックコンピューティング研究会で発表されていた研究
Session1: リソース構築
メディアミックスとローカライズに着目したマンガ・アニメ・ゲームに関する翻案関係のLOD作成
大石康介 (筑波大), 三原鉄也 (筑波大), 永森光晴 (筑波大)
この研究はMAG(漫画,アニメ,ゲームをまとめた呼称)といった多数のメディアに進出しているメディアミックス作品の情報を体系化しデータベースとして構築する際の問題点をLOD(Linked Open Data)によって解決するものです.
我々がMAGの作品を検索する際,多くのシリーズや派生作品があることで作品の概要が掴みづらかったり,どの作品から見ればいいかわからないことがあると思います.これが作品に関する情報が構造化されていないことと,海外展開の際にその国の文化などに合わせて内容を一部変更するローカライズに起因すると筆者らは考え,WikipediaとBook☆Walkerのデータを利用し,シリーズの情報と個々の作品の情報をLODを用いて構造的にデータ化する手法を提案しています.また実際に作品を同定することができるかを検証しています.今後はデータ数や情報源を増やすことによって信頼度や作品の網羅率を上げることが述べられていました.
日本のMAGなどの文化はCool Japanとして注目されており,今後さらに活性化が見込まれます.その中で重宝される研究だと思いました.(二宮)
漫画における台詞発話者の自動判定に向けた技術的困難性による整理とデータセット構築手法の検討
阿部和樹 (明治大), 中村聡史 (明治大)
漫画を機械的に分析する上で,どのキャラクタがセリフを発しているかという情報は重要です.しかし,セリフを囲う吹き出しの形状やその位置はバラついており,簡単に処理することができません.そこで,この研究ではセリフや吹き出しにはどのような要素があり,どう難しくしているかを事例ベースで分類することで,機械的に処理する上で解決すべき問題を整理しています.例としては吹き出しのしっぽがあるものは判定しやすいが,ないものは判定が難しいことなどが挙げられていました.また自動化する上で必要となる正解データセット構築のためのアノテーションシステムを実装しています.これは発話者とセリフの近さに着目し,セリフを発話していると考えられるキャラクタにドラックアンドドロップすることでアノテーションできるものとなっています.今後はこのシステムの改良するとともに,このシステムで得られるデータを用いて自動判定手法を検討するとのことです.
この研究は漫画を分析する上で地盤となる研究で,新たなプラットフォームになりそうだと感じました.(二宮)
この研究に関しましては著者の阿部が発表報告記事の中で詳しく述べていますのでそちらもご覧ください.
第2回コミック工学研究会で「漫画における台詞発話者の自動判定に向けた技術的困難性による整理とデータセット構築手法の検討」というタイトルで発表してきました(阿部和樹)
登場人物の行為に着目したシーンの言語化に関する一検討: 少女漫画を対象として
井上須美 (関西大), 安尾萌 (関西大), 松下光範 (関西大)
電子コミック市場が拡大する中で,ユーザが自身の求める作品を探すのが困難になっていることがあります.有効な検索手段の1つとして内容情報に基づく検索が考えられますが,そのためには必要な情報を記述するデータが必要となります.そこでこの研究では,シーン検索のための基礎検討として,シーンを記述したデータセット構築手法の提案とその問題点を考察しています.具体的には区切られたシーンをテンプレートに従って人手で要約し,言語化したデータセットを構築しつつ,その内容を観察しています.その中で行為者と行為対象者が逆になる事象が多く観測され,記述のテンプレートの見直しが展望として挙げられていました.
この研究の目的であるシーン検索は,ユーザが漫画の内容を知らずに検索できるという面においては中村研究室のネタバレ研究と通ずるところを感じました.まだ基礎的な研究ではありますが,システムとして実装されるのが待ち遠しい研究です.(二宮)
特別企画(はこだて未来大学主催,コミック工学研究会共催)
山田胡瓜先生x松原仁先生:マンガを創る人工知能
この企画では「AIの遺伝子」をはじめとして人工知能を題材とした漫画を多く書いてらっしゃる山田胡瓜先生と,はこだて未来大学の教授にして人工知能に関する多くの著作,プロジェクトに関わる松原仁先生による対談が行われました.
その中では山田先生が漫画家の視点,松原先生が工学的な視点で漫画を切り取り,AIによる創作活動や漫画執筆支援,AIと人間の創造プロセスの違いなど様々な話を交わしていました.後半には質疑が行われ,漫画家はどこまで機械に任せることを許容できるか,AIによる漫画生成の現状など活発な議論が行われました.
漫画家さんのお話を初めて聞く機会となり,漫画家を目指すきっかけから現在までの苦労など様々な話を聞けて,非常に新鮮でした.また松原先生は人間と機械それぞれの得手不得手を踏まえた活用と,AIを活用する上での線引きの考えなどをお話しされていて,感銘を受けました.(二宮)
Session2: 語学学習支援
英語多読学習支援のためのManga Vocabulometerの開発
大工勇樹 (大阪府立大), 岩田基 (大阪府立大), 黄瀬浩一 (大阪府立大)
この研究は英語の多読学習を支援するシステムを漫画に応用したManga Vocabulometerの開発に関するものです.
英語学習の方法の一つである多読学習は,わからない単語を飛ばしてとにかく英語を読む学習法です.その支援ツールとして,わからない単語を推定し,復習に役立てるVocabulometerが開発されました.漫画は絵があるため,文だけに比べて理解しやすく,多読に有効であると著者らは考え,Vocabulometerを漫画に応用したものがこの研究です.システムとしてはアイトラッカーで視線を観測し,目の動きに付随する特徴量を用いてわからない単語を推定するシステムとなっており,SVMで実装しています.単語の推定は高い精度で実現していますが,誤推定もあり,文章の長さで特徴量を正規化することが展望として挙げられています.
漫画で楽しみながら英語を学習できるとモチベーションにも繋がるため,日本人の英語学習の新定番になるかもしれません.(二宮)
オノマトペの音響類似度に基づくシソーラスマップ
兼岩尭希 (名古屋工業大), 中村剛士 (名古屋工業大), 加納政芳 (中京大), 山田晃嗣 (情報科学芸術大学院大)
漫画は海外にも大きく広がっており,各国の言語に合わせて翻訳されています.また,漫画には多くのオノマトペが使われていますが,日本語を母国語としない人がその意味を推定することは難しく,翻訳時に適切な訳を当てられていない場合があります.そこでこの研究ではオノマトペの音響的特徴をMFCCベクトル化し,類似度を計ることで,意味を推定する手法を提案しています.また歩く/食べるに関するオノマトペで評価実験を行い,発音が類似するものがまとまり,提案手法がうまく機能していることが示されました.また他の手法と比較する実験も行いましたが,違いがあまり見られず,提案手法の有効性を示すには至りませんでした.さらなる発展のためにはデータセットを増やすことや,音の類似の定量的評価を挙げていました.
オノマトペという言語学的なものに音響・音声分野のアプローチをとっていることに驚きました.(二宮)
コミックを利用した日本語教材の作成支援システム開発の一検討
桑野将豪(立命館大),山西良典(立命館大),西原陽子(立命館大),竹井尚子(サイモン・フレーザー大)
海外で日本語を教える際,既存の教材だけでは網羅できない日本語独特の多彩な表現や,ニュアンスの違いを教えるために,アニメや映画などを活用する場合があります.しかし,その探索やシーンの抽出を全て手作業で行うのは非常に大変です.そこで,この研究では漫画で特定の単語や言い回しを含むシーンを検索できるプロトタイプシステムを提案しています.実際にこのシステムで会話を抽出することができましたが,コンテクストを把握できるコマは少なく,複数コマの提示などで対応する必要があると述べていました.今後に関しては実際の現場でのユーザスタディを通じて改善するそうです.また議論の中では難しい応用的な技術よりも,当たり前のことが簡単に使えることを重視しているという現場の声が紹介され,研究者が考えるニーズとユーザのニーズの違いなどにも焦点が当てられていました.
海外の方が日本語を学ぶきっかけの一つに漫画などの日本のカルチャーが挙げられることがあります.そのことを加味すると漫画などを教材として使うことは非常に有効であると感じます.(二宮)
Session3: 漫画の実世界活用
震災アーカイブを活用したマンガ制作ワークショップ ―東日本大震災の証言記録のマンガ化
三原鉄也 (筑波大),木野陽 (マンガ家、フリーランス)
近年、大規模災害の資料をディジタルアーカイブ化しWebで公開する取り組みが行われていますが、こうした膨大な資料の内容を理解し文脈を反映したメタデータを作成することは困難です。ここで、マンガ制作において作画資料としてアーカイブが利用されていることや、アーカイブがマンガの根拠や信ぴょう性を提供することから、著者らはマンガとアーカイブ資料に相互活用の可能性があると考えました。これを検証するため、東日本大震災の震災アーカイブを利用したマンガをマンガ制作初心者がプロの指導を受けながら描くワークショップを開催しました。結果として、参加者全員がマンガを完成させることができましたが、マンガの描き方の効率的なレクチャーやメタデータ整備、またツール開発に課題があり、より高品質なマンガ制作ワークショップの手法を検討していく必要があると挙げられています。
こちらの発表では研究者だけでなくプロの漫画家さん視点の議論や意見交換が活発に行われ、コミック工学研究会を通じてコミックに関する研究が今後ますます活性化されていくのだろうと感じながら発表を聞かせていただきました。
またこれは余談ですが、僕も一時期漫画を描いていた時期があり(小学生の頃ですが…)、プロの漫画家さんを交えたワークショップに参加された学生さんを少し羨ましく思いました。(松山)
実環境と紐づいた物語コンテンツによる周遊行動の誘発
安尾萌 (関西大) ,宮本誠人 (関西大) ,樋口友梨穂 (関西大) ,三溝俊介 (関西大) ,松下光範 (関西大)
日常生活において人は慣れ親しんだ環境で行動を最適化しているために、周辺環境に対する気づきを得ることが難しくなってしまいます。ここで、ポケモンGOのようにコンテンツを用いて周遊行動を誘発するものはありますが、リワード獲得などが目的で実環境へ興味が向かないという問題があります。本研究は、実生活と物語コンテンツを連動させたアプリケーションを使用して周遊行動の誘発と環境への新しい気づきへ誘導することを目的としています。具体的には、実環境をベースとした物語を長編小説と4コマ漫画の2つのプロトタイプを用いたアプリケーションを開発しました。漫画と小説で実世界との紐付けや解釈プロセス、コンテンツ生成などで違いがあり、今後の展望としてプロトタイプを用いたユーザ観察を行う必要があると述べています。
僕は普段地元を散歩することが多いのですが、散歩ですら決まったルートを通ってしまうことがあります。このシステムが実装されれば、普段行かない場所を知ることや、見知った場所に新たな体験を付加することなどができると考えられ、このシステムを使ってみたいな、と思いながら発表を聞かせていただきました。(松山)
Session4: コンテンツ分析
漫画における著作者の癖の定量化による著作者の推定
安田幸生 (慶應義塾大),佐藤雅明(慶應義塾大),村井純(慶應義塾大)
電子コミック市場は年々拡大していますが、それを維持・拡大するには漫画の質が大事であると考えられます。ここで、著者らは漫画の質は著作者の個性に影響され、著作者の個性を定量化することで漫画の質を測ることができるのではないかと考えました。本研究は、従来小説の分析として用いられている計量文献学を適用し、単語の出現頻度やコマ数、キャラの出現頻度を特徴量として著作者を推定することによって定量化の可能性を検討することを目的としています。実際にSVMとランダムフォレストを用いて推定を行ったところ、Top1で53%、Top3で72%の精度で推定することができ、個性が存在する可能性が示唆されました。一方で、個性の存在は著作者より漫画単体に対して存在するかもしれないと述べられていました。
漫画の著作者推定に絵柄ではなく文字数や要素の出現頻度等を用いているところが興味深かったです。またこちらの発表者が発表前に好きな漫画を紹介したことを契機に、後の発表者も自分の好きな漫画を紹介する流れが生まれたのがおもしろかったです。(松山)
コマ配置による視線誘導がマンガの読みに与える影響の分析
村上聖将 (はこだて未来大), 角康之 (はこだて未来大)
漫画はコマ配置によって視線誘導を行っており、基本的には右から左、上から下というように読み進めるように配置されています。しかし、夏目房之介はその配置に従わない変則的なコマ配置をして視線誘導を行うことで、読者の没入感を深められると述べています。本研究ではこの仮説が支持する視線誘導効果とそれによって読者が受ける影響を分析しました。実際に変則的な配置を含めた漫画を読ませて視線計測と印象に関するテストを行った結果、仮説通りとはいきませんでしたが、ページ構成を変化させることによる視線行動の変化や、吹き出しやキャラクター、ページの右上が視線誘導効果に強く影響することが明らかになりました。また最後に、漫画に対する人間の認知を明らかにする研究として興味深いと述べられていました。
視覚情報がとても重要な漫画において、人間の認知特性や視覚的効果を明らかにすることはとても有用であり、今後漫画を描く人にとっての指針などにも使えると感じました。また本研究は2ページの見開きを前提とした従来の漫画形式での実験だったため、今後電子コミックで使われている1ページのみの形式だとどのような視線の動きが出るかを分析してみてもおもしろいのかな、と思いました。(松山)
Session5: 生成・加工
LSTMを用いた会話からの表情判定によるマンガ生成の一検討
迎山和司 (はこだて未来大)
漫画は絵と物語が一体となった表現であり,人工知能を用いて生成する場合,その両方を考える必要があります.人工知能技術においては絵の生成や物語の生成はそれぞれ行われていますが,絵と物語を生成する研究はあまり行われていません.そこでこの研究では既存の漫画をメタデータとして記述し,登場人物のセリフと表情を時系列に並べたスクリプトとして表現し,LSTMを用いて新しい漫画の生成を行なっています.着想としてはセリフに対し,妥当な表情をつけることで新しい漫画を創作できるという迎山氏の考えがあります.結果として漫画を生成することはできき,キャラクタのポーズやカメラワークを自動化することにより表現の拡張をしたいとのことです.また質疑においてはコミック工学における機械学習メソッドの活用を含めた活発な議論が行われました.
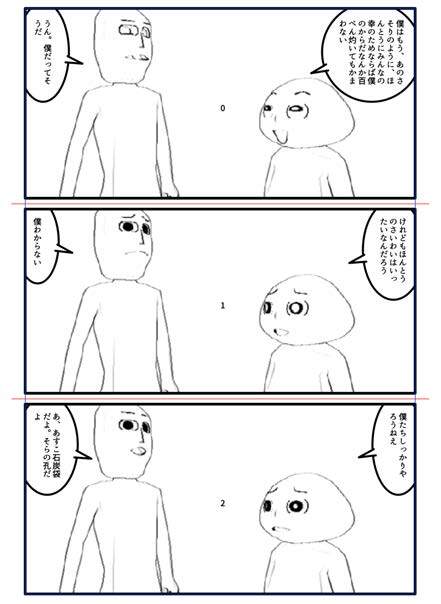
この発表の中ではデモが行われていたのですが,流れがとてもスムーズでプレゼンターとしてもとても参考になると感じました.(二宮)
画像検索を用いた漫画キャラクターの彩色フレームワークの検討
池澤大 (立命館大), 藤田宜久 (立命館大), 山西良典 (立命館大), 仲田晋 (立命館大)
この研究は漫画においての自動彩色に関する研究です.
日本の漫画は白黒の漫画が多いですが,電子コミック化による印刷コストの低減や海外コミックはカラーが主流であることなどから,カラー漫画の需要は高まっていると言えます.しかし人手で色をつけるのは大変なため,機械による自動彩色を検討します.漫画のキャラクタはあらがじめキャラクタごと色が決まっていることが多い,特にメディアミックス作品はWeb上にキャラクタのカラー画像があることが多いため,それを利用してこの研究では,彩色したいキャラクタのグレースケール画像とキャラクタ名,作品名を入力としてキャラクタのカラー画像をWeb上で検索し,Pix2pixで学習,モデル化することで自動彩色するシステムを作成しました.その結果違和感のない着色をすることができました.展望としては学習時に入り込んだ他のキャラクタを除去することや,グレースケールだけでなくトーン,二値画像への対応が挙げられました.
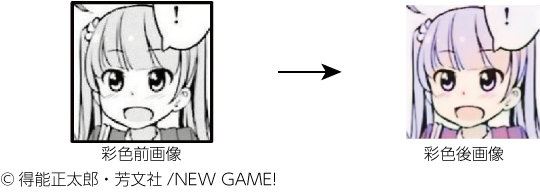
発表を聴講していた漫画家さんからはすぐ使いたいと言う声も上がっていました.(二宮)
Session6: 機械学習
BERTを用いたコミックにおける固有表現の抽出と類似語の推定に関する検討
朴炳宣 (関西大), 松下光範 (関西大)
この研究はコミックの固有表現抽出におけるニューラルネットワークの可能性を模索するものです.
漫画における固有表現はかなり独特で,自然言語処理的に解析するためにはうまく固有表現を抽出しなければなりません.先行研究としてCRFを用いた技法が紹介されていましたが,精度は52.6%とまだまだ難しいことがわかります.そのためこの研究ではニューラルネットワークを利用した機械学習による固有表現抽出精度の向上を検討します.ここでは通常の自然言語処理分野で性能を発揮しているBERTやLSTM,CRFを組み合わせた5つのモデルを比較しています.結果としては既存手法より高い精度を出すことができましたが,BERTは意図とは異なる挙動を示しました.今後は適切なコーパスの作成や,パラメータ調整,BERTを改良した機械学習アルゴリズムの使用が挙げられていました.議論ではコミック が会話ベースであるため,通常の自然言語処理と異なることが話題にあがり,コミックの独自性とそれゆえの分析の難しさが露わとなっていました.
日々改良がなされている機械学習アルゴリズムのフロントエンド技術が使われていてとても勉強になりました.(二宮)
時系列深層学習を用いた会話内の知識含有文の抽出手法
松岡航平 (立命館大), 西原陽子 (立命館大), 山西良典 (立命館大)
3人以上のコミュニケーションの場において前提知識の違いによって,会話の内容を理解できないことがあります.このような知識含有発言を抽出するために会話文が基軸となっているコミック のセリフを分析することによってどのようなタイミングで知識含有発言が発生し,どのように説明しているかを解き明かす研究となっています.セリフを知識を含むかをラベリングし,単語と話し方の平均ベクトルを作成し,LSTMで推定します.結果,72%の精度で推定できました.今回は知識を含む発言が少なかったり,単語,話し方ベクトル作成時の問題点があげられ,これらを解決することでさらなる改善が見込まれます.
コミュニケーションの問題を漫画を用いて解決する発想に非常に驚きました.またコミュニケーション,コミック 工学双方で有用な研究だと感じました.(二宮)
感想
10月と言えど,北海道は寒かったです.
未来大の近くにダムがあったのですが,とてもよかったです.是非行ってみてください.(二宮)

笹流ダム.紅葉が綺麗でした
函館に向かう前に雪虫騒動を知り、5年ぶりの飛行機で偏頭痛と乗り物酔いで最悪の気分で函館に到着しました。実際は雪虫もいなかったし時間が経って体調も回復したため、研究会には万全の調子で参加できました。よかったです。
コミック工学研究会は今回が2回目でまだ黎明期と言えると思いますが、黎明期ならではの研究会の雰囲気や想いを聞き、感じることができてとても有意義でした。今後機会があればまた参加してみたいです!(松山)

関西大の松下先生と