はじめに
中村研究室B4の木下裕一朗です.2024年1月22~23日に伊豆大島で開催された第121回CN研究会にて「スポーツにおけるネタバレ画像のデータセット構築と判定手法の検討」を発表しましたので,その報告をさせていただきます.
研究概要
録画や見逃し配信を利用してスポーツの試合を見ようとしたときに,試合視聴前にネタバレに遭遇してしまった経験はないでしょうか?スポーツ観戦の醍醐味の一つは,予期せぬ試合展開を楽しむことであるため,ネタバレは試合の視聴体験を低下させてしまいます.スポーツのネタバレ防止についての研究は様々行われていますが,画像によるネタバレを防止する手法は確立されていません.本研究では画像によるネタバレに着目し,まずネタバレ画像が判定可能か検証を行いました.また本研究でのネタバレ画像判定手法によって,80%以上の正答率でネタバレ画像を判定することができました.

ネタバレ画像(NBAの公式YouTubeチャンネルより)
ネタバレ画像の判定可能性について検証するため,本研究では,①ネタバレ画像のデータセット構築 ②ネタバレ画像判定手法の提案とその精度評価 を行いました.
①ネタバレ画像のデータセット構築
本研究ではYouTubeのサムネイル画像に着目し,5つのスポーツ(野球・サッカー・バスケットボール・アメリカンフットボール・バレーボール)の画像を収集しました.また,ラベル付与を行うにあたってネタバレ判断基準を統一するために,ネタバレ画像を「試合結果の予想がつく画像」と定義しました.3名でラベル付与を行った結果,全体としてはネタバレ画像の割合が0.24であることがわかりました.アメリカンフットボールとバレーボールについてはネタバレ割合が極端に低く,ネタバレ画像のデータ数が十分でないと考えたため,分析と判定には野球・サッカー・バスケットボールのデータのみを用いました.
②ネタバレ画像判定手法の提案とその精度評価
構築したデータセットを分析した結果,ネタバレ画像には以下の4つの特徴があると考えました.
- 試合の最終結果が表示されている
- 選手の表情が笑顔もしくは吠えている
- 選手が喜びや興奮を表現するポーズをとっている
- 同一チームの選手が集まって歓喜している

これらの特徴をもとに,本研究ではネタバレ画像の判定手法を3つ提案しました.
- Non-AI手法:OCR,感情推定,姿勢推定を組み合わせてネタバレ判定する手法(Google Cloud Vision APIとYOLOv8を利用)
- Vision-Direct手法:OpenAI Vision APIを利用し,4つのネタバレ特徴を入力してネタバレ判定をVisionに行わせる手法
- Vision-Text手法:OpenAI Vision APIを利用して画像内容を言語化し,その言語化したものに含まれている単語をもとにネタバレ判定する手法
構築したデータセットを用いてネタバレ判定を行った結果,F値はVision-Textがもっとも高く,Non-AIがもっとも低いことがわかりました.また,Vision-Textは正答率0.85という結果でした.Vision-Directについては,どの指標においても0.70以上の結果であったため,こちらもネタバレ画像の判定において有効である可能性が示されました.Non-AIは,再現率は高いものの適合率が非常に低いため,画像の多くをネタバレと判定しており,精度は高くないと考えられます.
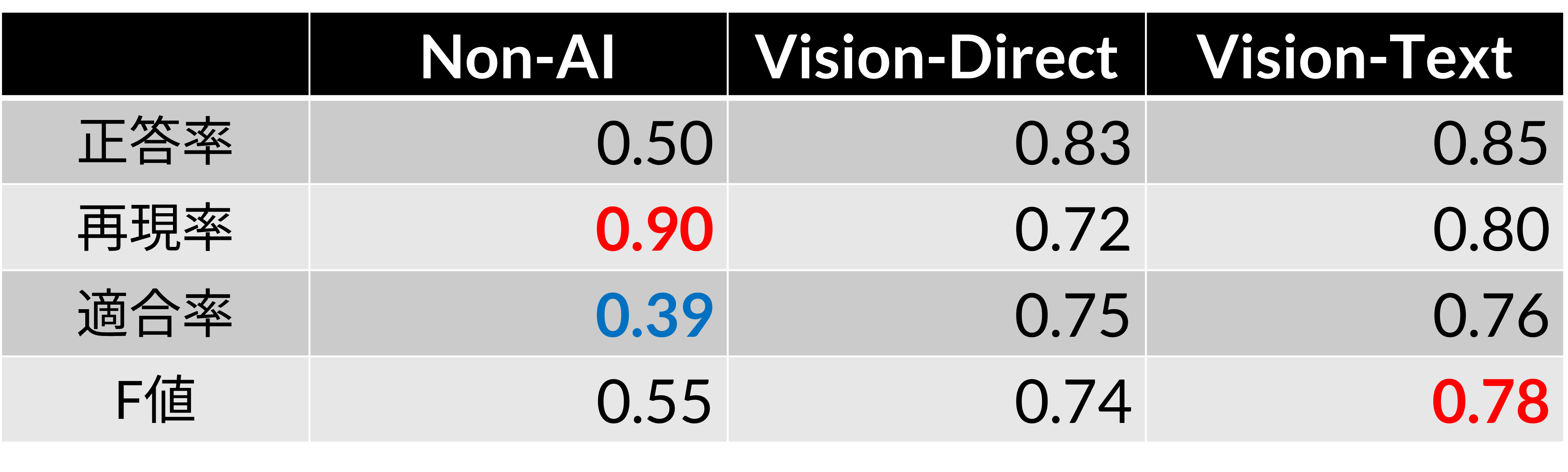
ネタバレ判定結果
今後は,Vision-Direct,Vision-Text手法の判定精度向上を目指します.また,今回構築したデータセットはラベルの一貫性について問題が見られたため,データセットの再構築を行う予定です.
発表スライドと書誌情報
おわりに
発表は相変わらず緊張しましたが,面白い研究発表を多く聞けたり,懇親会で他大学の方と交流することができたりして,とても楽しかったです.また今回は天候に恵まれず,伊豆大島に行くことができるのか,家に帰ることができるのかハラハラしましたが,それもなかなか味わうことのない体験だったと思っています.

港から眺めた日没

大島牛乳のアイスクリーム
最後になりますが,サポートしてくださった中村先生,相談にのってくださった研究室のみなさんに感謝申し上げます.ありがとうございました.
ピンバック: 中村研究室 2023年度の成果 | 中村聡史研究室
ピンバック: CollabTech2024にて”Detecting Sports Spoiler Images on YouTube”というタイトルで発表しました(木下裕一朗) – 中村聡史研究室